本博客 hjy-xh,转载请申明出处
三.函数式编程——模块化且可重用的代码
(读书笔记:JavaScript函数式编程指南)
今日分享
- 方法链与函数管道的比较
- 管道函数的兼容条件
- 柯里化的函数求值
- 部分应用和函数绑定(略)
1 方法链与函数管道的比较
之前提到了连接一系列函数的方法链,从而揭示了一种与众不同的函数式编程风格。还有一种称为管道的方法也可以用来连接函数。
函数的输入和输出对于了解函数本身是十分重要的。Haskell(发音为/ˈhæskəl/)中使用一种符号来描述函数。
如图一:

在函数式编程中,函数是输入和输出类型之间的数学映射。举例来说,一个简单的函数 isEmpty,它接收一个字符串并返回一个布尔值,就像这样表示:
1 | isEmpty :: String -> Boolean |
如图二:

该函数是所有 String 类型输入值到所有 Boolean 值之间的引用透明映射。该函数JavaScript的lambda描述形式如下:
1 | // isEmpty :: String -> Boolean |
了解函数作为类型映射的性质是理解如何将函数链接和管道化的关键:
- 方法链接(紧耦合,有限的表现力)
- 函数的管道化(松耦合,灵活)
1.1 方法链接
map和filter函数都以一个数组作为输入并返回一个新的数组。这些函数都可以通过Lodash封装的隐式对象紧密地连接在一起,从而在后台实现对新数据结构的创建。
这是上一次分享中一个栗子:
1 | _.chain(names) //<--- 初始化函数链(创建惰性计算函数链来处理给定的数组) |
比较命令式代码,这的确是一个能够极大提高代码可读性的语法改进。然而,它与方法所属的对象紧紧地耦合在一起,限制链中可以使用的方法数量,也就限制了代码的表现力。这样就只能够使用由Lodash提供的操作,而无法轻松地将不同函数库的(或自定义的)函数连接在一起。(尽管使用 mixin 的方法可以扩展一个对象的功能,但这就需要自己去管理 mixin 对象本身。这里不做讨论)
从高阶函数角度来看,可以一组对数组操作的简单方法序列表示为图三所示的形式。打破函数链的约束就能够自由地排列所有独立的函数操作,而可以使用函数管道来实现这一目的。

1.2 函数的管道化
函数式编程能够消除方法链中存在的限制,使得任何函数的组合都更加灵活。管道是松散结合的有向函数序列,一个函数的输出会作为下一个函数的输入。图四抽象地说明了以不同类型对象作为输入的函数的连接方式。
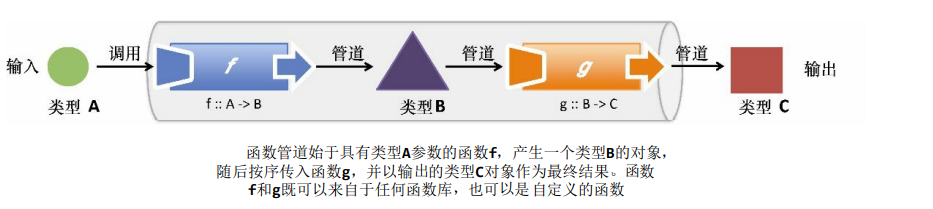
这也是面向对象设计模式中的管道与过滤器模式,它是从函数式编程衍变而来的(其中的过滤器就是各个函数)。
比较图三和图四就会发现一个关键的区别:方法链接通过对象的方法紧密连接;而管道以函数作为组件,将函数的输入和输出松散地连接在一起。但是,为了实现管道,被连接的函数必须在元数(arity)和类型上相互兼容。
2 管道函数的兼容条件
面向对象的编程在一些特定情况下(其中之一是认证与授权)偶尔会使用管道。而函数式编程将管道视为构建程序的唯一方法。
通常来说,对于不同的任务,问题的定义与解决方案间总是存在很大的差异。因此,特定的计算必须在特定的阶段进行。这些阶段由不同的函数表征,而所选函数的输入和输出需要满足以下两个兼容条件。
- 类型——函数的返回类型必须与接收函数的参数类型相匹配。
- 元数——接收函数必须声明至少一个参数才能处理上一个函数的返回值。
2.1 函数的类型兼容条件
在设计函数管道时,函数的返回类型与函数的接收参数之间具有一定程度的兼容性是极其重要的。
由于JavaScirpt是弱类型语言,因此从类型角度来看,无须像使用一些静态类型语言一样太过关注类型。因此,如果一个对象在应用中表现得像某个特定类型,那么它就是该类型。这也被称为鸭子类型:“如果走起来像鸭子,并且像鸭子一样叫,那这就是一只鸭子。”
JavaScript的动态调度机制会尝试在对象中查找属性与方法,而不关注类型信息。虽然这非常灵活,但开发者仍然需要了解一个函数所期望的参数类型。使用清晰的定义(例如在代码中使用 Haskell 符号标记)可以使程序更易理解。
正式地讲,仅当 f 的输出类型等同于函数 g 的输入时,两个函数 f 和 g 是类型兼容的。举例来说,一个处理用户输入的简单程序:
1 | trim :: String -> String <--- 截掉首末空白符 |
此时,normalize的输入与trim的输出服从兼容性的对应关系,因此可以在一个简单的管道序列中调用它们:
1 | // trim :: String -> String |
类型固然重要,但在JavaScript中,更关键的是函数元数的兼容性。
2.2 函数与元数:元组的应用
元数定义为函数所接收的参数数量,也被称为函数的长度(length)。尽管在其他编程范式中,元数是最基本的,但在函数式编程中,引用透明的必然结果就是,声明的函数参数数量往往与其复杂性成正比。例如,操作一个字符串的函数很可能比具有 3 个或 4 个参数的函数简单得多:
1 | // isValid :: String -> Boolean |
只具有单一参数的纯函数是最简单的,因为其实现目的非常单纯,也就意味着职责单一。因此,应该尽可能地使用具有少量参数的函数,这样的函数更加灵活和通用。然而,总是使用一元函数并非那么容易。例如,在真实世界中,isValid 函数可能会额外返回一个描述错误信息的值:
1 | isValid :: String -> (Boolean, String) // <--- 返回含有验证状态或错误信息的结构体 |
但如何返回两个不同的值呢?函数式语言通过一个称为元组的结构来做到这一点。元组是有限的、有序的元素列表,通常由两个或三个值成组出现,记为(a, b,c)。由此,可以使用一个元组作为isValid函数的返回值——它将状态与可能的错误消息捆绑,作为单个实体返回,并随后传递到另一个函数中(如果需要的话)。
下面详细探讨一下元组。元组是不可变的结构,它将不同类型的元素打包在一起,以便将它们传递到其他函数中。将数据打包返回的方式还包括字面对象或数组等:
1 | return { |
但当涉及函数间的数据传输时,元组能够具有更多的优点。
- 不可变的——一旦创建,就无法改变一个元组的内部内容。
- 避免创建临时类型——元组可以将可能毫不相关的数据相关联。而定义和实例化一些仅用于数据分组的新类型使得模型复杂并令人费解。
- 避免创建异构数组——包含不同类型元素的数组使用起来颇为困难,因为会导致代码中充满大量的防御性类型检查。传统上,数组意在存储相同类型的对象。
JavaScript并不原生地支持Tuple数据类型。例如,给定一个Scala中的元组定义:
1 | var t = (30, 60, 90); |
可以像这样访问各个元素:
1 | var sumAnglesTriangle = (t._1 + t._2 + t._3 = 180); |
但是JavaScript已经提供了实现元组所需的所有工具,实现如下:
1 | const Tuple = function (/* types */) { |
上面定义的元组对象是不可变且长度固定的数据结构,是可用于在函数间通讯的存储了 n 个不同类型值的异构集合。举例来说,可以用元组来快速构建如Status这样的值对象:
1 | const Status = Tuple(Boolean, String); |
下面利用元组来完成用户输入验证:使用了元组的 isValid 函数
1 | // trim :: String -> String |
在软件开发过程中,二元组出现得非常频繁,将其设定为一等的对象非常具有实际意义。在ES6解构赋值特性的支持下,可以简明地将元组值映射到变量中。如下代码使用元组创建了一个名为StringPair的对象。
1 | const StringPair = Tuple(String, String); |
元组是减少函数元数的方式之一,但还可以使用更好的方式去应对那些不适于元组的情况。通过引入函数柯里化不仅可以降低元数,还可以增强代码的模块化和可重用性。
3 柯里化的函数求值
将函数的返回值作为参数传递给一元函数是十分容易的,但如果目标函数需要更多参数呢?
为了理解JavaScript的柯里化,首先必须了解柯里化的求值和常规(非柯里化的)求值之间的区别。
JavaScript是允许在缺少参数的情况下对常规或非柯里化函数进行调用的。换句话说,如果定义一个函数f(a, b, c),并只在调用时传递a,JavaScript运行时的调用机制会将b和c设为undefined。如图五:

再看柯里化函数,它要求所有参数都被明确地定义,因此当使用部分参数调用时,它会返回一个新的函数,在真正运行之前等待外部提供其余的参数。图六能够直观地表现这一点:

柯里化是一种在所有参数被提供之前,挂起或“延迟”函数执行,将多参函数转换为一元函数序列的技术。具有三个参数的柯里化函数的定义如下:
1 | curry(f) :: (a,b,c) -> f(a) -> f(b)-> f(c) |
以上符号描述表明,curry是一种从函数到函数的映射,将输入(a, b, c)分解为多个分离的单参数调用。在纯函数式编程语言中(如Haskell),柯里化是原生特性,是任何函数定义中的组成部分。由于JavaScript原生不支持柯里化函数,因此需要编写一些代码来实现它。
我们先从二元参数的手动柯里化例子开始,代码如下所示。
1 | function curry2(fn) { |
柯里化是一种词法作用域(闭包),其返回的函数只不过是一个接收后续参数的简单嵌套函数包装器。以下是一个简单应用:
1 | const name = curry2(function (last, first) { |
curry2 能够胜任简单的任务,但是当构建更复杂的功能时,就需要能够自动处理任意数量参数的柯里化函数。
curry是一个很长且复杂的函数,因此与其去解释它令人头疼的实现,不如讨论更为有用的东西(者可以在Lodash和Ramda中找到curry及其另两个版本curryRight和curryN的实现)。可以使用R.curry对任意数量参数的函数进行自动的柯里化。
可以将自动柯里化想象为基于声明参数的数量人工创建对应嵌套函数作用域的过程。柯里化fullname函数如下所示:
1 | // fullname :: (String, String) -> String |
多个参数会被通过如下形式转换成多个一元函数:
1 | // fullname :: String -> String -> String |
现在来看一些柯里化的实际应用。尤其是,它可以用于实现以下两种流行的设计模式。
- 仿真函数接口
- 实现可重用模块化函数模板
3.1 仿真函数工厂
在面向对象世界中,接口是用于定义子类必须实现的契约抽象类型。如果创建的接口包含函数findStudent(id),那么实体类必须实现此函数。下面这段Java示例代码说明了这一点:
1 | public interface StudentStore { |
这段代码显示了同一个接口的两个实现:一个从数据库读取;另一个从缓存读取。
但是从调用代码的角度来看,它只关心方法的调用而并不关心来自哪个对象。这就是面向对象设计模式中工厂方法模式的美妙之处。只要使用一个函数工厂就可以了:
1 | StudentStore store = getStudentStore(); |
当然,函数式编程的实现是不容错过的,其解决方案就是柯里化。通过分别创建在存储数据和数组中查找学生对象的函数,就能够将这段Java代码翻译为JavaScript:
1 | // fetchStudentFromDb :: DB -> (String -> Student) |
由于这两个函数都是柯里化的,因此可以使用一个通用工厂方法findStudent将函数的定义与求值分离,而其具体的实现细节可能是任意一个查找函数:
1 | const findStudent = useDb ? fetchStudentFromDb(db) : fetchStudentFromArray(arr); |
现在findStudent可以传递给其他模块,而其调用者无须了解其具体实现。从可重用的角度来看,柯里化也能够帮助开发者创建函数模板。
3.2 创建可重用的函数模板
假设开发者需要配置不同的日志函数来处理应用程序中的不同状态,比如错误、警告以及调试信息等。函数模板会根据创建时的参数数量来定义一系列的相关函数。这里用一个日志相关的库Log4js举例子。以下是一些基本设置:
1 | const logger = new Log4js.getLogger("StudentEvents"); |
在Log4js的辅助下,还可以做到更多。假设需要在弹出的窗口中显示消息,可以通过配置一个appender来实现:
1 | logger.addAppender(new Log4js.JSAlertAppender()); |
也可以通过配置一个布局,使其输出 JSON 而不是纯文本格式:
1 | appender.setLayout(new Log4js.JSONLayout()); |
开发者可能设置很多的配置,而将这些代码复制并粘贴到每个文件中会导致大量重复。使用柯里化来定义一个可重用的函数模板(如下所示的日志函数模板),将带来最大的灵活性和重用性。
1 | const logger = function (appender, layout, name, level, message) { |
通过柯里化 logger,可以集中管理和重用适用于任何场合的日志配置:
1 | const log = R.curry(logger)("alert", "json", "FJS"); |
如果要在一个函数或文件中记录多条错误日志,可以灵活地设置除最后一个参数之外的其他参数:
1 | const logError = R.curry(logger)("console", "basic", "FJS", "ERROR"); |
curry函数的后续调用在后台被执行,最终生产一个一元函数。事实上,可以通过现有的函数创建新函数,并将任意数量的参数传递给它们,从而逐步实现函数构建。除了能够有效提升代码的可重用性之外,将多元函数转换为一元函数才是柯里化的主要动机。
柯里化的可替代方案是部分应用和函数绑定,它们受到JavaScript语言的适度支持,以产生更小的功能,在插入功能管道时也能很好地工作。
4 部分应用和函数绑定
部分应用是一种通过将函数的不可变参数子集初始化为固定值来创建更小元数函数的操作。简单来说,如果存在一个具有五个参数的函数,给出三个参数后,就会得到一个、两个参数的函数。和柯里化一样,部分应用也可以用来缩短函数的长度,但又稍有不同。因为柯里化的函数本质上是部分应用的函数,所以这两种技术往往会被互相混淆。它们的主要区别在于参数传递的内部机制与控制。
柯里化在每次分步调用时都会生成嵌套的一元函数。在底层,函数的最终结果是由这些一元函数的逐步组合产生的。同时,curry 的变体允许同时传递一部分参数。因此,可以完全控制函数求值的时间与方式。
部分应用将函数的参数与一些预设值绑定(赋值),从而产生一个拥有更少参数的新函数。该函数的闭包中包含了这些已赋值的参数,在之后的调用中被完全求值。
现在,既然已经明确两者的不同,下面继续研究partial函数可能的实现方式,如下所示。
1 | function partial() { |
对于部分应用和函数绑定的讨论,再次使用Lodash,因为它对函数绑定提供了比Ramda更好的支持。然而从表面来看,_.partial与R.curry的使用方式非常相似,并且都支持使用各自的占位符对象对参数进行占位。应用于之前看到的 logger 函数,就通过部分应用部分参数来创建更具体的行为:
1 | const consoleLog = _.partial(logger, "console", "json", "FJS Partial"); |
下面用该函数加强对curry与partial之间差异的认识。在应用了三个参数之后,生成的consoleLog函数会在调用时接收另外的两个参数(一次性的,而不是一步一步地传入)。与柯里化不同,只使用一个参数调用consoleLog并不会返回一个新的函数,而是会以undefined作为最后一个参数
来执行。但是,可以像下面这样继续使用_.partial 将部分参数应用于consoleLog:
1 | const consoleInfoLog = _.partial(consoleLog, "INFO"); |
柯里化是一种部分应用的自动化使用方式,这是它与partial本身的主要区别。另一种类似的JavaScript原生技术称为函数绑定,即Function.prototype.bind()。但其作用与partial有所不同:
1 | const log = _.bind(logger, undefined, "console", "json", "FJS Binding"); |
_.bind的第二个参数undefined是什么呢?使用绑定能够创建绑定函数,该函数可在一个所属对象的上下文中执行(传递undefined表示该函数将在全局作用域中运行)。来看看_.partial和_.bind的一些实际用途:
- 核心语言扩展
- 惰性函数绑定
4.1 核心语言扩展
在增强语言的表现力方面,部分应用可用于扩展如 String 或 Number 这样的核心数据类型的实用功能。注意,如果语言中加入了可造成冲突的新方法,以这种方式扩展语言可能会使代码很难在平台升级的过程中移植。考虑下面的例子:
1 | // Take the first N characters |
在实现自己的函数之前,首先要进行存在性检查,以便适用于新的语言版本升级:
1 | if (!String.prototype.explode) { |
在一些特定情况下,部分应用会失效,例如当用于(如setTimeout)延迟函数时。这时就需要使用函数绑定来实现。
4.2 延迟函数绑定
当期望目标函数使用某个所属对象来执行时,使用函数绑定来设置上下文对象就变得尤为重要。
例如,浏览器中的setTimeout和setInterval等函数,如果不将 this 的引用设为全局上下文,即window对象,是不能正常工作的。传递 undefined 在运行时正确设置它们的上下文。例如,setTimeout可用于创建一个简单的调度对象来执行延迟的任务。以下是使用_.bind 和_.partial的示例:
1 | const Scheduler = (function () { |
使用Scheduler,可以将任何一段代码包含在函数体中延迟的执行(运行时是无法确保计时器的精准的,但这是另一个问题)。由于 bind 和 partial 都是返回另一个函数的函数,因此可以很容易地嵌套使用。如前面的代码所示,每一个延迟操作都基于函数绑定和部分应用函数的合。在函数式编程中,函数绑定并不像部分应用那么有用,而且使用起来也比较投机,因为它会重新设置函数的上下文。
部分应用和柯里化都是十分有用的技术。柯里化技术使用得非常广泛,通常用于创建可抽象函数行为的函数包装器,可预设其参数或对其部分求值。其优势源于具有较少参数的纯函数比较多参数的函数更易使用。两种方法都有助于向函数提供正确的参数,这样函数就不必在减少为一元函数时公然地访问其作用域之外的对象。这种分离参数获取逻辑的方式使得函数具有更好的可重用性。更重要的是,它简化了函数的组合。

